知识图谱(KG)预训练是近几年来知识图谱研究中比较热门的话题,通过预训练的方式从大规模的知识图谱中提取知识的表示(结构化表示、文本表示、多模态的表示)用来辅助各种In-KG和Out-KG的任务。这次我们主要分享一些知识图谱预训练和基于知识图谱的推荐(KG4RecSys)的已有工作。
1. KG预训练¶
本页统计信息
-
本页约 2510 个字, 预计阅读时间 8 分钟。
-
本页总阅读量次
1.1 论文清单¶
1.1.1 In-KG tasks¶
- Improving Knowledge Graph Representation Learning by Structure Contextual Pre-training. IJCKG 2021
- Mask and reason: Pre-training knowledge graph transformers for complex logical queries. KDD 2022
1.1.2 Out-KG tasks¶
Language Modeling¶
- K-bert: Enabling language representation with knowledge graph. AAAI 2020
- Jaket: Joint pre-training of knowledge graph and language understanding. AAAI 2022
- Contrastive language-image pre-training with knowledge graphs. NIPS 2022
- Tele-Knowledge Pre-training for Fault Analysis. ICDE 2023
RecSys and Others¶
- Billion-scale pre-trained e-commerce product knowledge graph model. ICDE 2021
- Improving conversational recommender system by pretraining billion-scale knowledge graph. ICDE 2021
- Knowledge Perceived Multi-modal Pretraining in E-commerce. ACM MM 2022
- PKGM: A Pre-trained Knowledge Graph Model for E-commerce Application. Arxiv 2022
- Structure Pretraining and Prompt Tuning for Knowledge Graph Transfer. WWW 2023
Graph Pre-training Survey¶
- Graph Prompt Learning: A Comprehensive Survey and Beyond.
1.2 Taxonomic¶
知识图谱的预训练相关的论文可以从要解决的任务、KG的类型、进行一个初步的划分: - 解决的任务: - KG内任务:三元组分类、实体预测、关系预测、复杂推理 - KG外任务:推荐系统、知识问答、跨模态迁移、语言模型预训练、电信领域推理 - 预训练的KG类型: - 通用KG:FB15K-237,WN18RR,CoDeX - 领域KG:电商KG、电信KG - 训练方式: - 预训练任务的形式:自监督任务 - 结构预训练:利用三元组结构信息完成预训练,知识图谱中的实体保留embedding参与下游任务(显式) - 结合文本预训练:三元组展开成文本参与到预训练中,将知识图谱中的知识融入到LM的参数里(隐式) - 多模态预训练:多模态信息融合的预训练,包含图像、文本、KG图结构 - 下游任务应用方式: - Stand-up型:提供实体/关系的embedding作为额外的特征 - Fine-tune型:提供预训练模型进行下游任务的微调
常见的三种知识图谱预训练的范式: 1. 利用图结构进行预训练,用知识embedding的方式为下游任务提供辅助,代表性论文PKGM 2. 将KG融入到预训练的语料中,用一个预训练好的PLM微调来完成下游任务,代表性论文K-BERT,KTele-BERT 3. 利用图结构进行预训练,保留已知实体embedding的同时,将模型的参数迁移到下游任务的新KG中去,代表性论文KG-Transformer
1.3 经典工作¶
K-BERT: 通用域KG+LM预训练¶
- 原论文:K-bert: Enabling language representation with knowledge graph. AAAI 2020

这篇文章提出了一种将知识图谱融入到BERT预训练的过程中的方法,如下图所示,具体来说对于一个输入的句子,K-BERT先从外部知识库中检索出句子中的关键实体对应的知识然后将其展开成一个更长的文本序列,然后转换成对应的token序列,作者为此进一步设计了一个被称为soft position embedding的机制来进行相对位置编码,然后通过设计一个Visible矩阵来控制不同的token之间的可见情况(事实上改变了注意力如何施加),最终完成了文本的预训练。下图简单表示了这两项关键的设计:
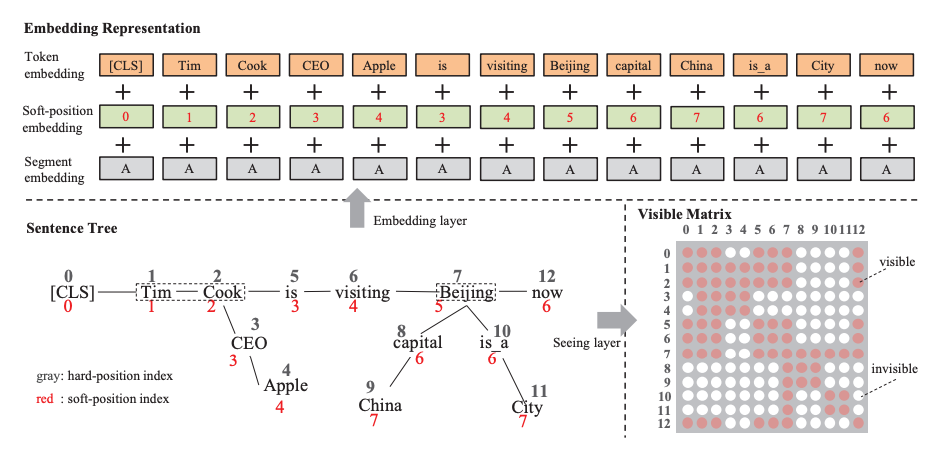
从中我们可以发现,这里的注意力设定规则如下: - 原始文本中的token之间遵循双向注意力原则 - 实体和对应的知识之间有双向的注意力,但是不匹配的实体和知识之间互相不可见 但是在下游任务中微调应用的时候,知识检索的这一部分不会被保留,还是当成原始的BERT进行微调。由于是通用域,该论文的主要下游任务是文本分类、NER和QA
KTeleBERT: 电信域KG+LLM预训练¶
- 原论文:Tele-Knowledge Pre-training for Fault Analysis. ICDE 2023
这篇文章主要提出了一种预训练电信领域知识的方法,将大量结构化和非结构化的电信领域数据进行了文本编码器的预训练,并用来解决各种复杂的下游任务。作者的主要贡献在于:
- 提出了适合电信领域场景的预训练任务
- 提出了自适应数值编码器来解决电信数据中数值编码的问题
- 设计了一个知识图谱中结构化知识的约束loss
文章中总的预训练任务还是BERT的MLM任务,但是作者针对不同形式的结构化电信领域数据设计了不同的prompt模版对其进行展开。
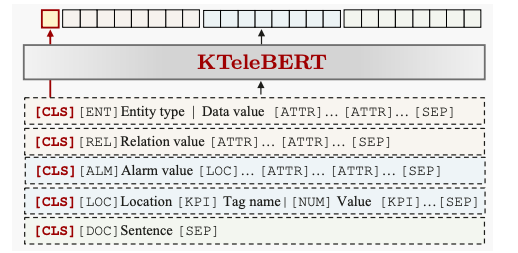
考虑到电信领域数据中大量存在的数值特征,作者设计了一个自回归的自适应数值编码模块进行数值特征的编码,并通过数值对比学习等多项预训练任务来完成数值特征的预训练

此外作者还提出了一个专家知识注入的预训练任务,对于电信KG中的一个特定三元组,通过提取其头尾实体和关系的文本表示来计算三元组的分数,并进行自监督的对比学习,以此让BERT模型可以感知到正确/错误的知识来达到专家知识注入的目的。
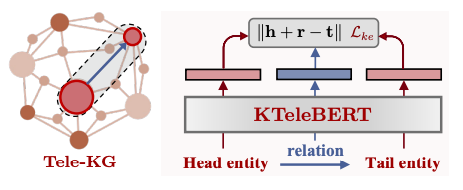
在具体的下游任务中,KTeleBERT将会作为一个文本编码器来提取电信域的文本特征并用来辅助下游的各项任务。
K3M: 多模态商品知识图谱预训练¶
这篇文章提出了一种大规模商品知识图谱预训练的方法,在面临有噪声和模态缺失的商品知识图谱的情况下,进行商品表示编码器的预训练和下游任务应用,具体的结构图如下图所示:

这里涉及到了三个模态,分别是图像、文本和KG结构,作者分别用了三个编码器来提取不同模态的特征,对于图像和文本都使用了Transformer架构的编码器,而对KG使用了一个GNN编码器。 为了解决可能存在的模态缺失问题,作者提出先分别进行模态编码,再进行多模态特征交互,再进行图结构聚合的pipeline,具体来说,对于一个商品的文本的图像信息,先分别进行编码,再通过一个图像文本交互器进行特征的交互,再将输出的图像和文本表示进行MLM的预测,同时通过pooling得到一个实体的多模态表示,并在GNN中将这个多模态表示和其他邻居节点的信息进行聚合,并通过一个自监督的链接预测任务来训练模型。
KGTransformer: 结构预训练和提示微调¶
KGTransformer提出了一种对知识图谱结构进行预训练并在下游任务中进行提示微调的框架,一方面,这篇文章提出了新的知识图谱预训练方法,另一方面,也做了新的下游任务微调的适配。预训练部分的模型架构如下:
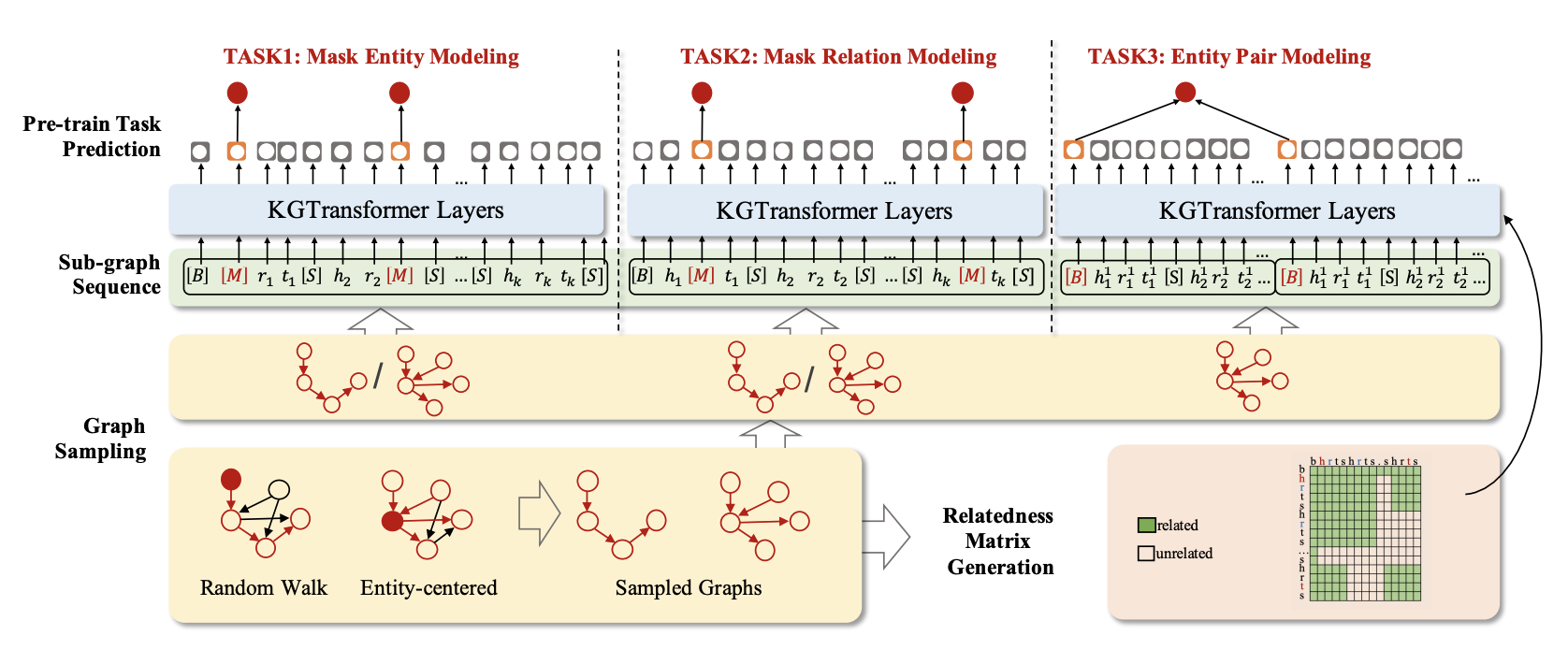
从图中我们可以看到KGTransformer通过对KG进行子图采样来得到一系列子图的序列作为模型的输入,然后设计一个相关性矩阵(对应BERT中的token mask)来控制每个实体/关系之间是否需要进行注意力的计算。在训练的过程中,KGTransformer参考BERT的MLM预训练方式提出了三个任务: ● MEM:对输入序列中的实体进行掩码并进行预测 ● MRM:对输入序列中的关系进行掩码并进行预测 ● EPM:同时输入两个子图,判断其中的某两个实体是否成对 在这个过程中,作者设计了三个特殊的token,B表示一个子图序列的开头,S是分隔符,M是Mask记号,这和BERT的设计也是类似的。
 对于不同的下游任务,KGTransformer需要一个不同的任务头G,再将其和任务所需的KG子图序列以及额外的信息进行拼接,然后获得embedding并输入到冻结的KGTransformer中,将获得的表示经过下游任务的分类头再进一步进行下游任务的预测。
对于不同的下游任务,KGTransformer需要一个不同的任务头G,再将其和任务所需的KG子图序列以及额外的信息进行拼接,然后获得embedding并输入到冻结的KGTransformer中,将获得的表示经过下游任务的分类头再进一步进行下游任务的预测。
Graph Prompt Learning Survey¶
-
原论文:Graph Prompt Learning: A Comprehensive Survey and Beyond
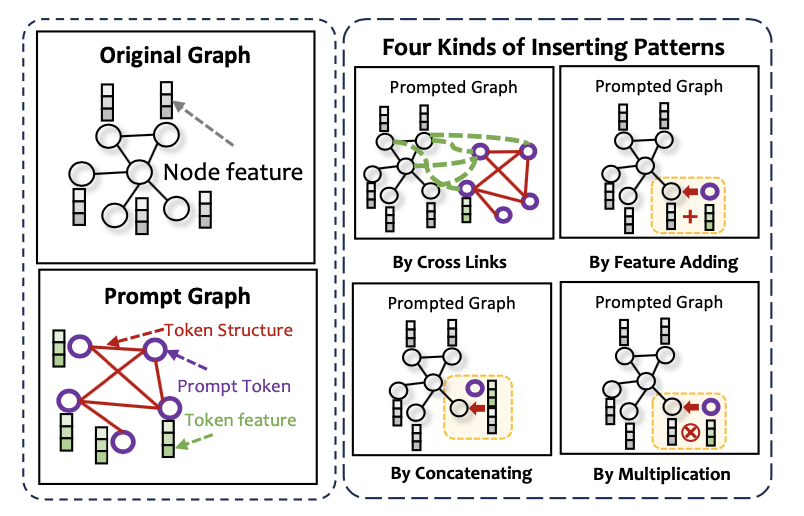
-
Prompt as tokens
- Prompt as graph
综述中还总结了Graph Prompt Learning的主要研究方向:

1.4 讨论与总结¶
关于知识图谱的预训练,有两个问题值得我们思考。第一个问题是为什么要进行预训练,第二个问题是为什么要进行下游任务的适配。 关于第一个问题,从上面介绍的几篇文章中我们可以发现,知识图谱的预训练主要目的有这样几种: 1. 利用知识图谱中存在的结构化知识来增强BERT等文本编码器的预训练,实现Knowledgeable的PLM,即KG被用作外部知识源增强语言模型、多模态模型的预训练。 2. 利用预训练任务提取KG中存在的结构信息,并将其泛化到新的KG或者新的任务上完成KG-related任务,即着眼于KG本身以及KG强相关的各类任务
Prompt tuning的设计重点在于完成预训练任务和下游任务形式上的统一,相比于直接stand-up式的利用方法来说,prompt tuning多了一个设计prompt模版的环节,让各种下游任务在形式上完成了统一。