大语言模型Large Language Model¶
本页统计信息
-
本页约 2430 个字, 预计阅读时间 8 分钟。
-
本页总阅读量次
最近半年以来大语言模型(Large Language Model)的技术随着ChatGPT的成功引起了广泛的关注,这篇博客就来整理一下和LLM有关的各项技术以及一些热门的大语言模型
1. 什么是大语言模型?¶
大语言模型(Large Language Model)实际上指的是基于Transformer架构的,拥有非常大参数量的(通常超过1B,作为对比,BERT-base的参数量是110M)的预训练语言模型(PLM)。最近非常火爆的LLM主要是以GPT为代表的Decoder架构的那一类模型。 什么是Decoder(解码器)架构呢?首先,和Decoder相对应的概念叫做Encoder,也就是编码器。我们可以简单地将Encoder理解为处理输入的模型,而Decoder理解为处理输出的模型,这样一类,任何模型实际上都可以看成是Encoder模型和Decoder模型的组合,那么语言模型就可以分成以下三类:
- Encoder-only的架构,模型本体是一个文本序列的编码器,Encoder-only架构的知名模型是BERT(虽然它不够大),RoBERTa等等,这类模型往往比较擅长做自然语言理解,也就是对输入的序列进行编码,提取到里面的特征。这类模型在预训练阶段采用了像是掩码语言模型(MLM)这样的训练任务。这类模型用到下游任务中的时候,往往需要接一些Output Head,最简单的时候就是一个全连接层,这些Output Head实际上就作为下游任务的解码器,完成了分类等任务。
- Encoder-Decoder架构,就是语言模型中既有Encoder也有Decoder,代表性的模型有BART、T5等等,这类模型非常适合做Seq2Seq的任务,比如翻译、摘要、问答等等。它们往往分别用一个Transformer架构的模型作为Encoder和Decoder,并用Encoder的输出作为Decoder的输入的一部分进行解码。
- Decoder-only的架构,就是模型本体是用来做解码的,常见的解码任务包括Next Word Prediction等,Decoder-only架构的代表性模型是GPT系列,他们都是用自回归的方式(也就是训练的时候进行Next Word Prediction)进行预训练的,训练完成后的模型也具有非常强的预测下一个单词的能力,可以用来进行各种生成任务。 那么Decoder-only的架构是不是就没有Encoder了呢?也不是,实际上在Decoder-only的架构中,Transformer的模块也在对输入序列进行编码,在最后一层也要用到句子末端输出的表示,通过一个线性层+Softmax预测下一个单词。 这三种架构的区别还在于Transformer中自注意力机制的不同,Encoder-only的模型中,注意力是双向的,也就是输入序列中的每个token之间都有注意力的计算。而Decoder-only的架构中,注意力是单向的,前面的token是“看不到”序列后面的token的,只有后面的token可以看到前面的token,Encoder-Decoder架构中,注意力又有更复杂的设计。
2. 提示学习Prompt Learning¶
提示学习Prompt Learning是近几年NLP领域非常热门的课题,它的核心思想其实就是将原本的wild data通过prompt模版的包装之后再输入到预训练的语言模型中去,而Prompt模版的设计需要考虑所使用的PLM的预训练任务,通过让Prompt模版和PLM的预训练任务的形式一致,来最大限度地激发PLM中已经具备的预训练知识,并获得更好的结果。
举个例子,BERT在预训练的时候往往通过MLM这样的任务,而MLM任务的具体处理方式是将一个句子中的某些单词替换成[MASK],然后用一个输出层去预测这些被掩盖掉的单词,从而完成预训练。那么我们在用BERT进行提示学习的时候,也需要将输入的句子处理成包含[MASK]的形式,然后用BERT去做编码,然后再将[MASK]这个token的output embedding通过输出层预测这个位置可能的单词,从而达成预测的目的。
对于不同的语言模型,我们需要设计不同的prompt,同时,prompt的用法也可以多样的,它非常适合用在一些zero-shot和few-shot的场景中。此外,前面说的这种prompt其实叫做hard prompt,也就是用明确的文本作为prompt模版,后来的文章逐渐研究出了一些soft prompt,不需要特定的文本,而是用一些向量来构造prompt,然后通过对向量进行调整达到学习的目的。实际上,hard prompt是在文本层面进行下游任务到预训练任务的adaption,它的选择空间中离散的,而soft prompt是直接在token embedding的表示空间中进行adaption,这些soft vector的变化是连续的。所以这两种方法又分别被称为discrete prompt和continuous prompt
3. 思维链Chain-of-thought¶
思维链(Chain-of-thought, CoT)最早应该是在《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》这篇文章中被提出的。CoT的核心思想是通过prompt引导大模型在进行复杂推理的时候先生成中间的推理过程,然后再做出推理。 后续的一些工作提出了更多的改进方案,比如自动化地进行CoT和多模态CoT等等,但总的来说,引导模型生成推理的中间过程这一思想都被保留了下来。这一块我也不太熟,就知道这一些。
4. 上下文学习In-context Learning¶
上下文学习是一种通过在prompt中给出一些例子(称为demonstrations),并让模型根据这些例子来对问题做出判断的prompt方法。下图就是一个经典的例子,上下文学习的核心思想就是让模型通过类比推理的方式来做出决策。综述《A Survey on In-context Learning》对于上下文学习给出了详细的讲解和分类。
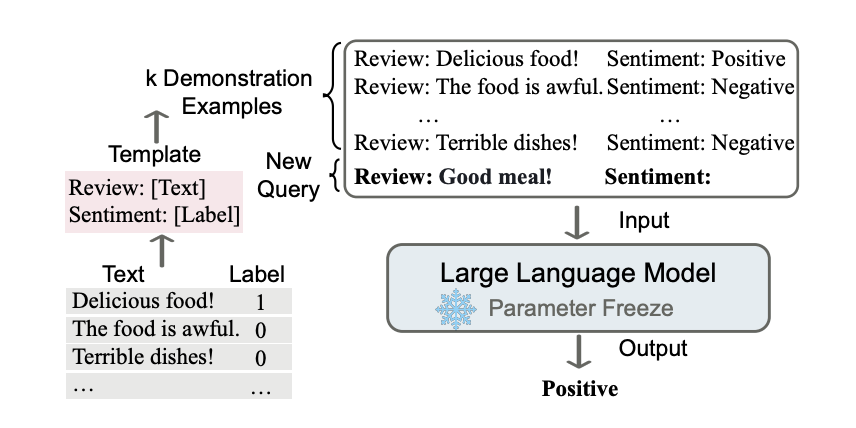
5. 指令微调Instruction Tuning¶
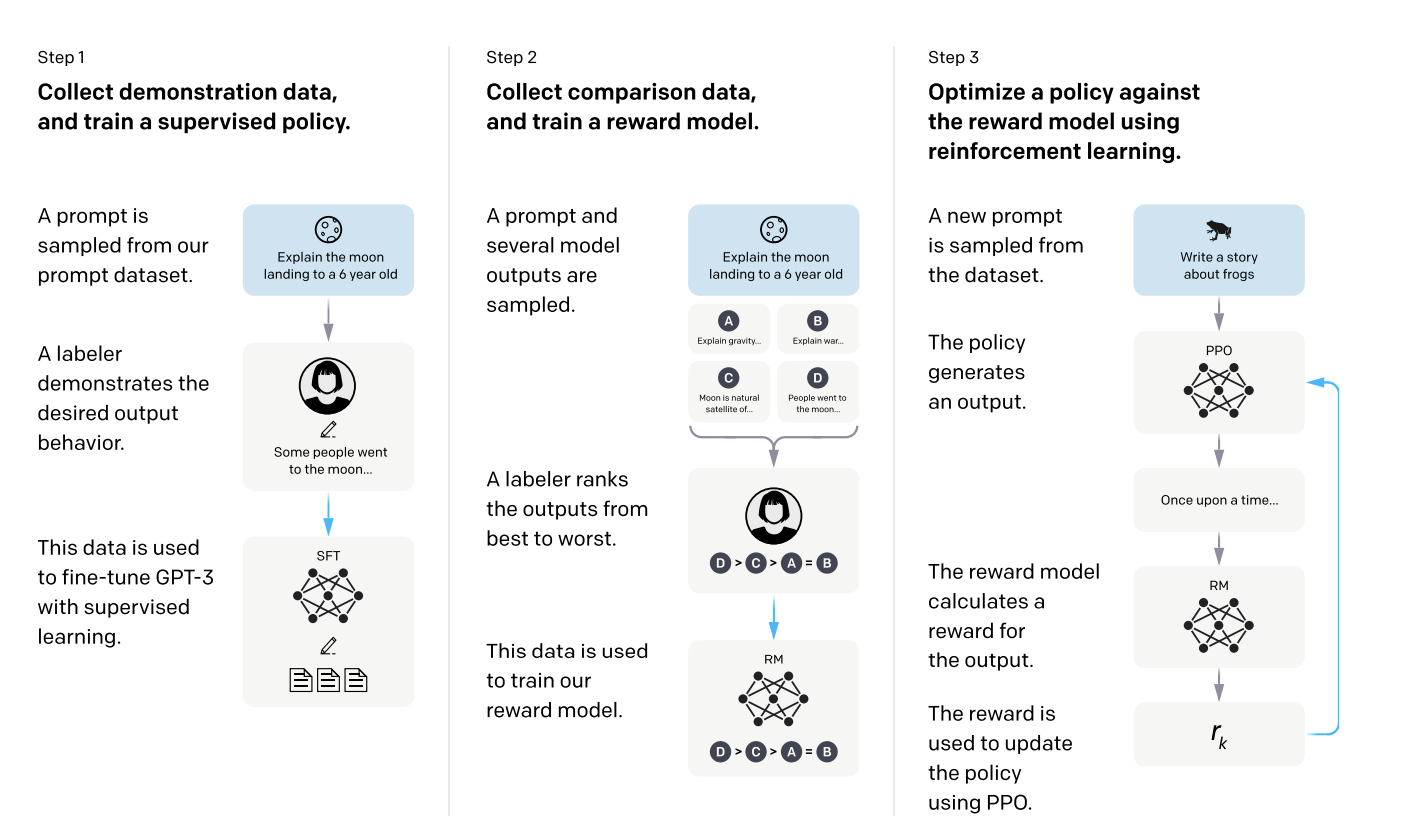
指令微调应该是在《Fine-tuned Language Models Are Zero-Shot Learners》这一篇文章中被明确提出的,它的具体做法就是在Prompt中加入明确的指令(指令要注重多样性,可以few-shot,但是种类多一点效果更高),并用这些prompt对模型进行微调,可以明显提升模型在Zero-shot任务上的性能。而让指令微调爆火的文章则是OpenAI提出了InstructGPT的这篇文章《Training language models to follow instructions with human feedback》,在这篇文章中,作者用一种三阶段的方式对大语言模型进行了微调:
- 第一阶段,用指令微调数据集进行有监督微调
- 第二阶段,利用人工标注数据训练一个奖励模型
- 第三阶段,用微调后的LLM和奖励模型+PPO等强化学习算法,将人类的偏好反馈给模型并对其进行微调
通过这样几步训练出来的模型可以生成更容易被人类所接受的回答,ChatGPT就是通过这种方式训练出来的。
6. 低秩微调 LoRA¶
前面说的思维链、上下文学习以及指令微调,其实都是Prompt层面的一些设计。而低秩微调属于大模型研究中的另一块内容——参数高效的微调(PEFT) 随着LLM的参数量越来越大,如果对整个模型进行fine-tune,那计算开销就太大了,所以参数高效的微调的基本想法是,减小微调的时候所需要调整的参数。P-Tuning就是一种很好PEFT的方法,它将大模型的参数固定,通过训练前缀的方式进行fine-tune,而LoRA则是另一种PEFT的方法,它通过矩阵分解的方式减少了需要微调的参数量。 比如,原本我们要fine-tune一个Transformer模型中的一个投影矩阵,现在LoRA的做法是将其参数固定住,然后另外学习一个矩阵,将这个矩阵加到原本的模型上面就可以得到fine-tune后的模型,然后LoRA又将这个要学习的矩阵分解成了两个更小的矩阵(比如将\(m\times n\)的矩阵分解成\(m\times r, r\times n\)的两个低秩的小矩阵),然后去微调这两个小矩阵就行。当使用微调后的模型进行推理的时候,只要将两个小矩阵相乘,加到原本的参数上就可以了。这种方法的好处在于极大地减少了需要微调的参数量,同时低秩又可以保证两个小矩阵能够在微调中充分学到东西。后续也有LoRA的一些改进,比如自适应的LoRA等等。
7. 一些现在比较热门的LLM¶
目前的话比较热门的LLM有GPT系列(包括ChatGPT,GPT-4等等),以及谷歌的BARD,还有Bing的,但是这些模型都是不开源的,我们只能通过网页版的Demo或者api来调用他们。 开源的LLM主要有清华推出的GLM系列(包括GLM-130B和ChatGLM-6B等等)还有Meta推出的LLAMA,从最近几个月的文章来看,LLAMA应该是目前开源模型中的主流,大部分文章都是用LLAMA模型做的实验。