因果注意力机制¶
本页统计信息
-
本页约 3961 个字, 预计阅读时间 13 分钟。
-
本页总阅读量次
1. Introduction¶
这次来读一些因果注意力(Causal Attention)有关的论文,学习一下注意力机制的设计要怎么和因果推断相关的技术产生关联。 注意力机制是一种非常常用并且热门的特征提取方法,它的核心思路在于设定一种自适应的权重计算方法,来实现输入特征的加权融合,这样一来,模型就可以根据数据的实际情况来动态调整对特征的不同部分的权重,实现更好的特征提取。比如,在图像分类任务中,对关键部分的像素分配更高的权重,这就是注意力的最直接的想法和解释。 但是,模型(不管是传统的机器学习模型还是后面的各种深度学习的模型),它们学到的都是输入X和输出Y之间的关联性,而模型在学习过程中,可能会被一些虚假的关联信息(spurious correlations)给误导,导致模型无法X和Y之间的因果关系,从而在面对Out-of-distribution(OOD)的数据集的时候,模型的性能会出现很严重的下滑。这些虚假的关联信息也被称为混淆量confounder
举一个例子,比如做图片分类,在训练数据集中,鸟的图片背景都是蓝天,猴子的图片背景全是树,那么模型学到的知识可能是蓝天对应鸟类,树对应猴子,这些知识并不是因果的,不是鸟类和猴子本身所具有的特征(比如鸟类长了翅膀,猴子的头比鸟大等等),而是一些虚假关联。这时候,如果测试集中的鸟类图片依然都是蓝天背景,而猴子图片依然全是树的背景,那么模型尚且可以在这种虚假的关联下维持表面的繁荣,但如果测试集上的图片存在OOD的情况,比如鸟类图片的背景都是树,那么模型的性能就可能出现非常严重的下降,比如把背景是树的鸟类图片全被分类成猴子,这就是模型没有学习到因果性所带来的坏处。
上面的例子就是很经典的学到spurious correlations导致模型泛化能力下降的例子,而注意力机制,虽然可以对输入的数据中的关键特征有所侧重,但依然无法解决这个问题,因为模型在学习过程中,依然有可能将confounder识别成关键信息进行学习,而在这样的关键信息上做注意力机制,无论如何也是难有好结果的。 为了解决这个问题,各种因果注意力(Causal Attention)机制被提出并用在不同的场景中,因果注意力机制的设计初衷就是希望模型能够聚焦于那些具有因果性的特征,在此基础上再进行注意力权重的计算,这样才能学到真正因果的信息,并能够泛化到测试数据上。 所以,这一次我们来读一些因果注意力相关的文章,来了解一下因果注意力机制究竟应该怎么设计。
2. 面向视觉-语言任务的因果注意力¶
原论文:Causal Attention for Vision-Language Tasks,发表于CVPR2021 这篇文章针对多模态的任务中存在的模型学到数据之间虚假相关性的问题,提出了一种使用因果注意力机制解决的框架,它对多模态学习的任务用如下结构因果模型进行建模:
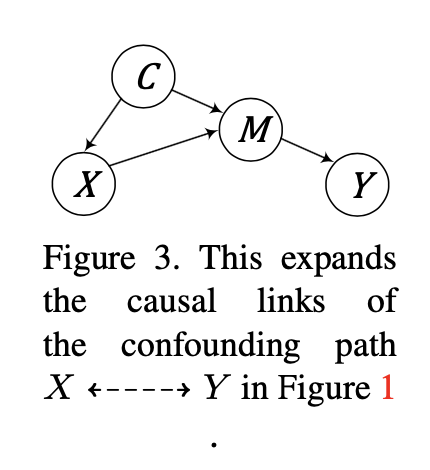 其中X和Y分别是输入数据和输出结果,M是数据X的中间表示,而C则是一个混淆变量,它会影响输入数据X本身和中间表示M,这就在因果图中形成了一条后门路径。
作者在论文中进一步提出了In-sample的Sampling和Cross-sample的Sampling方法,对输入数据X进行因果干预,以此来估计X和Y之间的因果效应,这其实就是前门调整,公式的表述如下:
其中X和Y分别是输入数据和输出结果,M是数据X的中间表示,而C则是一个混淆变量,它会影响输入数据X本身和中间表示M,这就在因果图中形成了一条后门路径。
作者在论文中进一步提出了In-sample的Sampling和Cross-sample的Sampling方法,对输入数据X进行因果干预,以此来估计X和Y之间的因果效应,这其实就是前门调整,公式的表述如下:
在这个公式里,\(\sum_z P(Z=z \mid X)\)被称为In-sample的Sampling,因为它的过程是对于一个X,得到中间变量Z的分布之后去进一步预测Y,这个采样过程是在数据X内部发生的,而\(\sum_x P(X=x)\)则被称为 Cross-sample的Sampling,因为它要遍历所有可能的x来预测Y的分布,这个过程实际上可以理解为,我们对数据集进行了去偏的操作,以Introduction中提到的鸟和猴子为例,前门调整公式一通操作的最终目的就是给数据集中加入一些鸟+树的例子让模型学习,这样就可以push模型去区分背景对分类结果是否真的具有因果关系,从而达到数据集去偏的目的。 模型的具体实现对前门调整做了进一步的改进,具体如下:
$$ P(Y \mid d o(X)) \approx \operatorname{Softmax}[g(\hat{\boldsymbol{Z}}, \hat{\boldsymbol{X}})], $$ 其中,IS-Sampling: \(\quad \hat{\boldsymbol{Z}}=\sum_z P(Z=z \mid h(X)) \boldsymbol{z}\), CS-Sampling: \(\quad \hat{\boldsymbol{X}}=\sum_x P(X=x \mid f(X)) \boldsymbol{x}\) 而模型具体实现的时候,使用了self-attention去提取了X和Z的特征,并且还进一步实现了注意力的层级化。总的来说,这篇文章的“因果注意力”有点挂羊头卖狗肉的意思,因为注意力并没有和因果推断中的公式紧密结合,而仅仅是作为提取特征的工具。
3. 用于无偏视觉识别的因果注意力¶
原论文:Causal Attention for Unbiased Visual Recognition,发表于ICCV2021 这篇文章提出了一种用于图像分类的因果注意力机制,我们先来看看它的故事是怎么讲的,以下一段是原文的翻译:
缓解混杂偏差的唯一解决方案是通过因果干预[42]。例如,Arjovsky等人[4]和Teney等人[49]建议在每个语境下收集 "鸟 "的图像(即调整 "鸟 "的语境)。在每个语境分割中(如 "地面"、"水 "和 "天空"),关注点不关注语境,因为它在分割中不再具有歧视性。因此,"地面/水面/天空+鸟 "的组合注意力将倾向于集中在 "鸟 "上,而不偏向于任何背景。然而,像上面那样进行因果干预是不现实的。 在实践中,不可能在任何上下文中收集一个类的样本,例如,在 "天空 "中很难找到 "鱼"。从技术上讲,这种没有上下文的类违反了偶然干预的confounder positiveitivity假设[25](见第4.4节中由违反引起的不良性能)。因此,我们必须将地面真实语境合并为更大的分割,以包括所有的类(例如,将 "水 "和 "地面 "合并为图2中的一个分割(左上方)) 然而,这种更粗略的背景将导致过度调整问题--干预不仅消除了背景,而且还伤害了有益的因果关系(例如,对象部分)。图2(左上)说明了一个真实的例子。再看,上述基于语境分割的干预措施删除了不同语境的非因果特征。不太幸运的是,"鸟 "的因果特征--"翅膀 "也被删除了(见注意中的红色虚线框)。这是因为所有在 "天空 "语境中的鸟都展开了翅膀:划分4不仅代表 "天空 "和 "草",也代表 "翅膀"。我们在第3.1节中正式提出这个问题的不当因果干预。
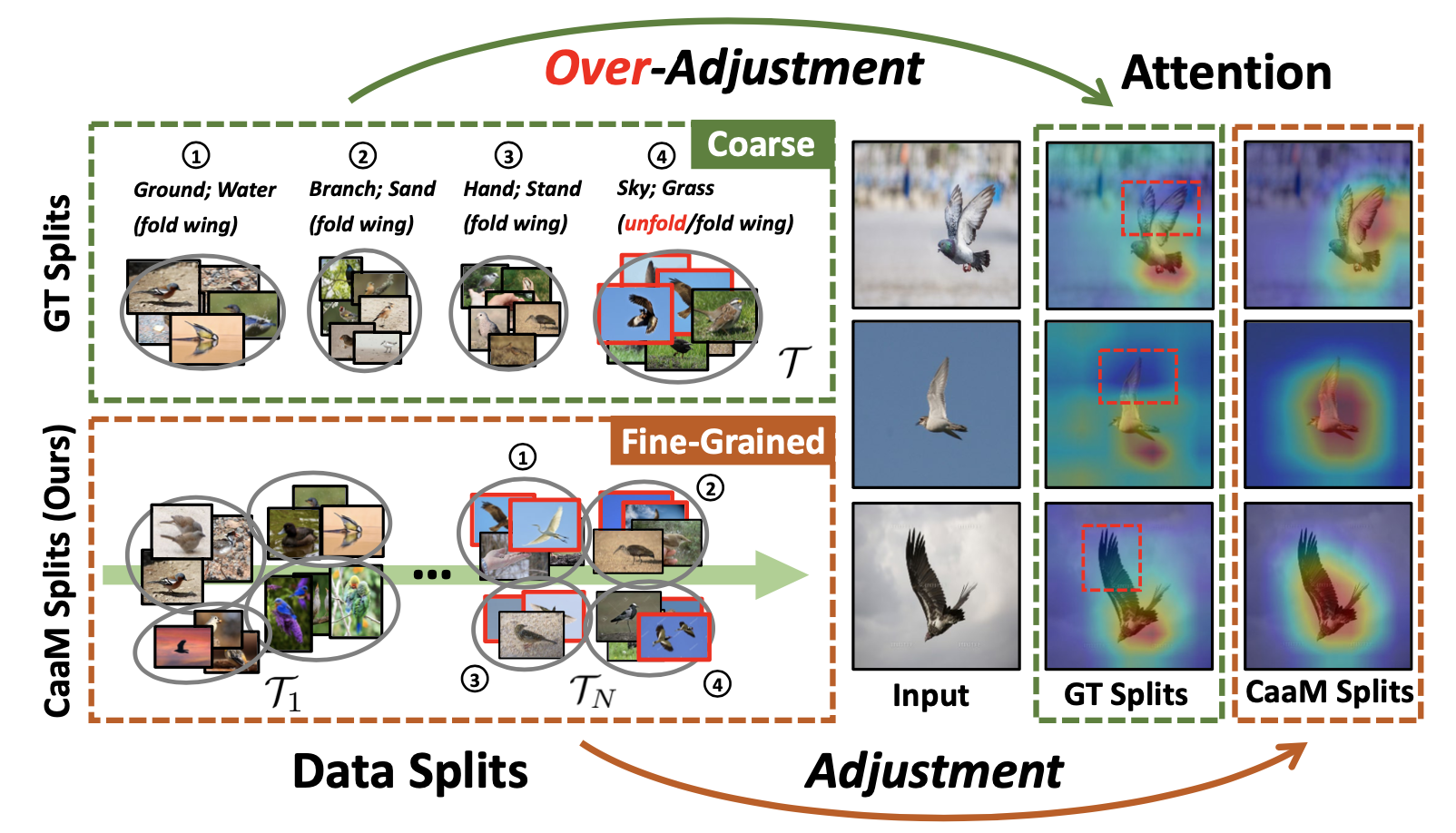
在这一段论述中,作者阐述了“物理意义上的因果干预”应该怎么做,然后说明这种方法存在的问题,包括:
1. 效率低下,不可能给所有的数据都进行物理干预
2. 干预的过程中容易丢失一些具有因果性的特征,比如鸟的翅膀和天空是绑定的,如果把背景换成草地,那鸟的翅膀可能也就缩回去了,这样一来模型就难以学习到翅膀→鸟类这样一条因果的知识
所以,作者在文中提出了一种因果注意力机制,并设计了对应的训练框架,下面我们可以具体来看看作者的方法是怎么设计的。
作者首先对可视识别的任务进行了因果图建模,如下图所示,X和Y分别代表输入数据和输出结果,M代表了中间变量,而S则是混淆量,a是原本的因果图,b是正确的干预后的因果图,而c是错误干预后的因果图。
 作者认为因果干预需要通过数据划分来进行,具体来说就是要对混淆变量进行划分,将混淆变量划分成一个集合\(\mathcal{T}\),然后用后门调整公示来计算X和Y之间的因果效应:
作者认为因果干预需要通过数据划分来进行,具体来说就是要对混淆变量进行划分,将混淆变量划分成一个集合\(\mathcal{T}\),然后用后门调整公示来计算X和Y之间的因果效应:
这个公式对应到具体的数据实例就是说我们要把数据中因果的部分(比如鸟和猴子)与所有混淆量(比如不同的背景)结合在一起进行模型的训练,这样才能消除训练数据带给模型的偏见。 同时作者还指出,有的方法进行的因果干预操作是错的,一些基于上下文的方法没有将因果图中的S和M解耦开,直接在M上进行调整,这反而会影响M的特征学习。 如果考虑到混淆量S和中间量M同时存在,我们在划分\(\mathcal{T}\)的时候,只针对不同的混淆量进行划分,那么X对Y的因果效应就会变成:
然而,如果在划分\(\mathcal{T}\)的时候,将M也作为了划分的依据,那么X和Y之间的因果效应计算方式就会变成:
这很明显和上面这个计算方式是有区别的,这样一来,我们在错误的划分下,对因果效应的估计就产生了错误。 因此,作者提出了一种新的交替式训练的框架,在每一步中都进行\(\mathcal{T}_i\)的划分并估计\(P(Y \mid d o(X))\),同时,为了实现confounder和mediator的解耦,作者设计了两个注意力模块\(A, \bar A\),分别用于提取具有因果效应的feature以及没有混淆的feature,那么这两个注意力模块实际上处于一个对抗的状态,一个需要提取具有因果性的特征,让模型能够做出鲁棒的预测,而另一个注意力模块则需要提取数据集中存在的bias 对于使用两个模块学到的特征,模型要保证能够做出稳定的预测,否则,他们可能不尊重训练数据生成的因果关系,所以模型对两个模块提取后的特征设置了一个交叉熵分类loss,形式如下:
这里的\(\widetilde{x}=x\circ \bar x\) 表示将两种特征结果相加来做预测。同时,还要给因果部分的特征再设置一个loss来保证模型能够学会提取因果特征并基于因果特征作出预测,具体形式如下:
这里的t代表了不同的数据划分,g表示分类器,在模型的推理阶段,\(g(A(x))\)会做出无偏的预测。 而为了分离两个不同的注意力模块,模型在训练的过程中需要进行一个min-max的博弈,这个过程分为两个阶段: - 第一阶段,对XE和IL进行训练,同时使用一个新的分类器h,对confounder feature进行分类,这一阶段要求h也要能做出准确的预测,具体的loss函数如下:
- 第二阶段,用非因果的特征去fool分类器h,使其无法做出鲁棒的判断,它的loss的形式是:
这里的\(\mathcal{T}_i(\theta)\) 是一个划分,表示某条数据属于某个划分。 具体实现这个因果注意力则简单了很多,就是在原本的注意力权重上做一下文章,在CNN模型中,这个注意力的实现方式如下:
这里就是把注意力没有提取到的那一部分作为confounder了。
4. 用于可解释和可泛化图分类的因果注意力¶
原论文:Causal Attention for Interpretable and Generalizable Graph Classification,发表于KDD2022
这篇文章是在GNN中使用了因果注意力来提取图的总体特征,它首先对图分类任务用如下因果图进行了建模:

这幅图是为了说明图特征提取过程中,图的一些shortcut feature会产生后门路径,对最终的预测产生影响,因此,作者提出了一种因果注意力框架来解耦因果特征和混淆特征,模型的示意图如下:
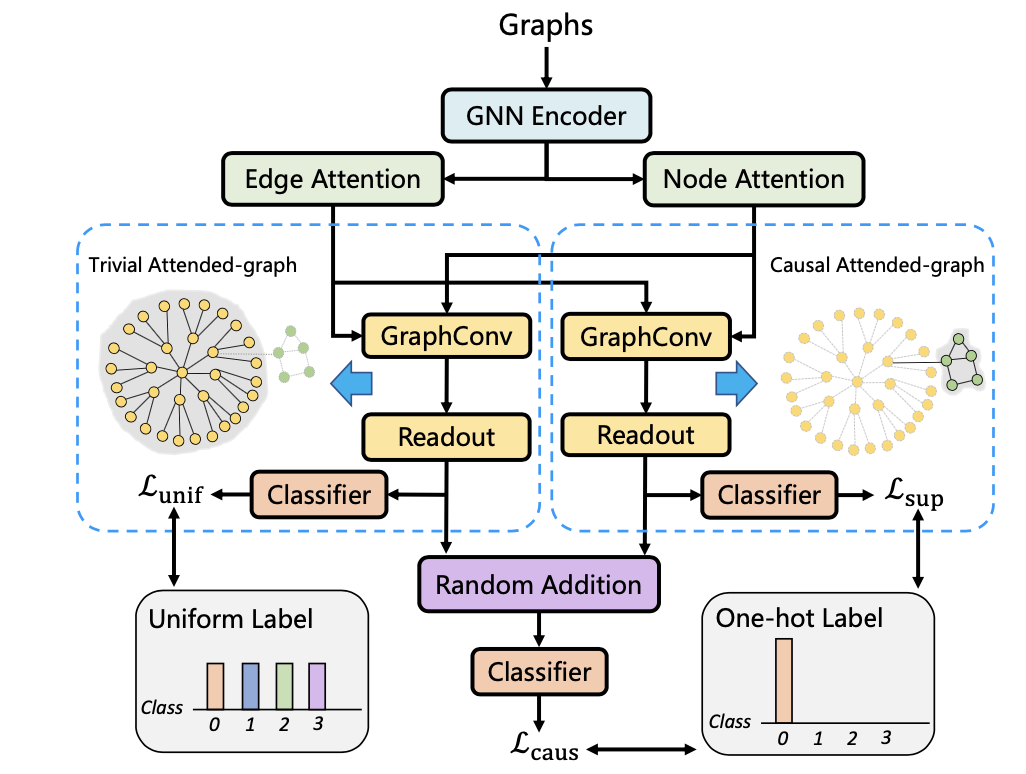
这里面,作者分别设置了两组注意力权重,来提取节点和边的两种特征,这个过程可以表示为:
并且两个权重加起来是1,实际上就是把整个特征做了一个解耦,然后分别提取两个特征,即因果特征、混淆特征,然后作者设计了三个loss函数来训练这两个特征:
对于因果特征,希望它能够接近ground truth,所以用一个交叉熵分类loss,对于混淆特征,希望它能够对分类结果不起作用,所以用KL散度让其逼近label的先验分布,如下所示:
然后论文还设计了一个intervention loss,用来表示因果干预的过程,具体的实现方式如下:
虽然看起来是对混淆变量进行了划分,但实际上论文是通过随机加的操作来实现。