大语言模型的Alignment¶
本页统计信息
-
本页约 998 个字, 预计阅读时间 3 分钟。
-
本页总阅读量次
我们发布了新的大模型对齐论文 Knowledgeable Preference Alignment for LLMs in Domain-specific Question Answering,ArXiv链接是https://arxiv.org/abs/2311.06503
1. 什么是Alignment¶
大语言模型中的Alignment实际上指的就是让大模型的输出结果和人类的需求能够对齐,一方面,LLM的输出需要符合人类输入的指令,这可以算是功能性需求,另一方面,模型输出的内容也应该能满足人类的偏好,比如语言风格与人类相近,对于政治敏感话题和非法内容实现过滤,从而保证输出的内容对于普通用户来说事可接受的。 在GPT系列模型中,开发者主要通过一种被称为人类反馈的强化学习(RL with Human Feedback, RLHF)的技术来实现这一目的,这个过程中,我们需要在原有LLM的基础上,训练一个奖励模型(Reward Model, RM),他的作用是对对模型的输出进行打分。在训练的过程中并让标注者对不同的结果进行排序,让人类喜欢的排序更高,而让人类不喜欢的结果排序更低,同时,基于这个排名,来优化RM的参数,之后再使用PPO等强化学习算法,将人类的偏好反馈通过RM打得分数反馈给LLM,通过这样的方式,ChatGPT实现了人类偏好和模型输出的对齐。
2. RLHF的缺陷¶
但是RLHF这套方法也有这非常明显的缺陷,首先,RLHF引入了RL的框架,这导致模型非常难以训练,并且InstructGPT的论文也表明,单纯采用RLHF会导致模型在通用域上的能力的退化,所以RLHF在训练的时候往往还会用一个KL散度来约束模型的输出,使输出的结果不偏离原本太多。 另外这一套流程也不够end-to-end,要分成三个阶段一步步进行。后续提出的各种LLM Alignment算法针对这几个问题进行了优化,设计出了很多新的Alignment方法。 - 这些新的Alignment方法的焦点就是RL-free
3. RRHF: Rank Responses to Align Language Models with Human Feedback without tears¶
这篇文章提出了一种直接使用不同来源的数据进行LLM Alignment的做法并称之为RRHF,它的具体做法是,对于给定的query,RRHF首先需要收集不同生成器(人、ChatGPT、待训练的LLM等等),然后给不同的回答进行偏好排序,以此来构建数据集。
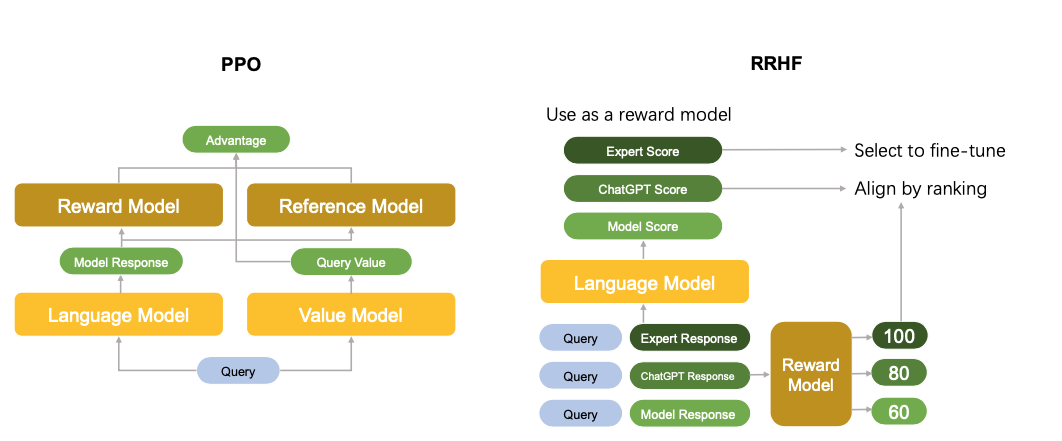
在训练阶段,RRHF对于同一个问题,将不同Generator生成的结果进行打分,并用排序损失来进行不同结果之间的对比,让高质量的回答获得更高的分数,同时维持原有的Finetune损失,进行多任务的训练。同时,RRHF用一个回答生成时,每个token对应的条件概率的平均值作为一个回答的分数,这样一来还避免了RM的训练,所以整个训练过程用一个SFT的阶段就可以完成。整个训练过程的loss可以表示为:
- 所以RRHF的具体方法实际上就是,对于一个给定的query,用不同的生成器去生成一些不同的答案,然后用一个规定好的打分方式对其进行打分,然后用这些数据一起进行SFT和Rank Loss的计算
4. RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment¶
RAFT提出了另一种新的大语言模型Alignment的方法,它的具体做法就是利用一个训练好的RM,直接进行训练数据的选择,将得分高的Query-Response对筛选出来,而将那些得分低的删除。
这种做法非常的直观,他基于这样一个简单而基本的事实,那就是:微调一个大模型,实际上只需要少量(几千条)高质量的数据就可以完成,也可以实现和人类偏好的对齐。很多时候我们微调不好不同的大模型,实际上就是因为训练数据的质量不够高,而RAFT则提出了,直接使用RM来进行高质量训练数据的筛选,从而达到利用高质量数据进行大模型微调的目的,它的核心算法如下图中的伪代码所示:
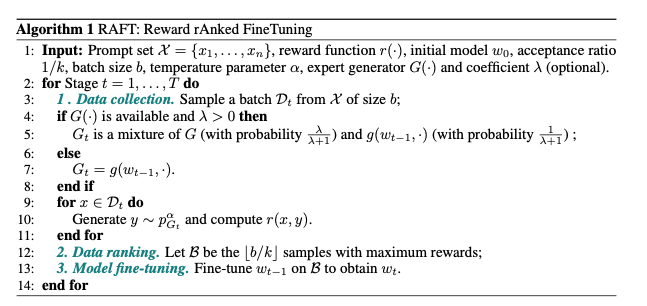
具体来说就是在给定的训练好的RM的基础上,在微调阶段直接进行高质量数据的选择。
5. PRO: Preference Ranking Optimization for Human Alignment¶
这篇文章提出的方法PRO是一个更新的Alignment算法,查看作者列表我们发现这篇文章和前面的RRHF一样,也是阿里巴巴达摩院产出的文章,他的主要新设计在于,对于一个Query所对应的多个Answer构成的偏序集,采用更加细粒度的方式进行对齐,具体来说,假设对于一个Query,我们有4个不同的Answer1,2,3,4(并且这四个橘子的偏好顺序是1>2>3>4),那么PRO会进行3次比较,第一次让A1>A2,A3,A4,第二次让A2>A3,A4, 第三次让A3>A4,具体来说可以参考下面这张图:
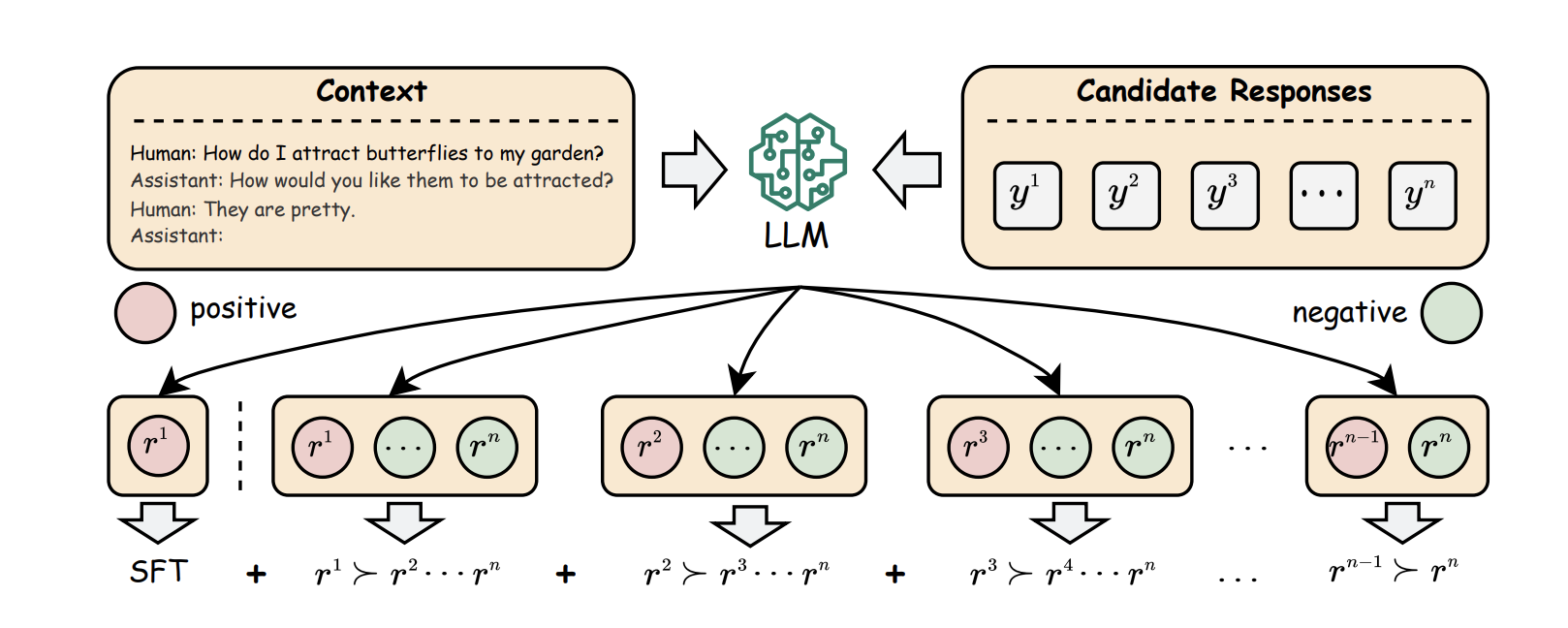 PRO部分的损失函数采用了对比学习的形式:
PRO部分的损失函数采用了对比学习的形式:
这里面的 \(\pi_{\mathrm{PRO}}\) 是需要被Fine-tune的LLM,而\(r\)则代表了奖励函数,这篇文章中所使用的奖励函数和RRHF中所使用的一样。最后,模型还需要加上SFT的Loss函数,并通过一个系数\(\beta\)和PRO损失组合,进行多任务的模型训练。