Causality01-因果推断与潜在结果框架
本页统计信息
-
本页约 1820 个字, 预计阅读时间 6 分钟。
-
本页总阅读量次
《Introduction to Causal Inference from a Machine Learning Perspective》by Brady Neal 学习笔记
0. Pre-requests¶
在正式学习因果推断和其相关理论之前,我们需要首先知道这样几个基本概念:
0.1 相关性和因果性¶
相关性代表了事物之前存在的关联,而因果性代表了事物之间的内在联系,在机器学习中,我们很多时候学到的都是数据与标签之间的相关性(当然这里说的是监督学习),模型在训练过程中可能会学习到数据中存在的一些shortcut feature,这就会导致模型依据shortcut feature做出判断,而不是根据数据和标签之间最本质的关系来做出判断。
两个变量X和Y之间如果有相关性,还无法判断它们之间的因果性
0.2 如何判断因果性¶
我们如何判断事物的因果性?这需要我们控制变量并且做随机对照试验(randomized controlled trial)来完成。我们要研究两个变量X和Y之间的因果性,那么就要控制其他所有无关因素不变,然后改变X,根据Y的变化情况来判断X和Y之间的因果性。 但是,随机对照试验是一种非常理想的情况,因为控制变量实际上是一件非常麻烦的事情,有很多现实的因素需要考虑(比如科学伦理),这导致随机对照试验的代价非常大。 因此,代替随机对照试验,使用观察数据是一个诱人的捷径。观察性数据是由研究者在没有任何干扰的情况下简单地观察受试者获得的。这意味着,研究者对处理方式(treatment)和受试者没有控制权,他们只是观察受试者并根据观察结果记录数据。从观察数据中,我们可以找到其行动、结果,以及已经发生的信息,但无法弄清他们采取具体行动的机制。 对于观察到的数据,核心问题是如何获得反事实的结果。例如,我们考虑"如果这个病人接受了不同的药物治疗,会不会有不同的结果?" ,回答这样的反事实问题具有挑战性,原因有两点: - 第一,我们只观察到事实的结果,而没有观察到如果他们选择了不同的治疗方案可能发生的反事实的结果。 - 第二,在观察性数据中,治疗通常不是随机分配的,这可能导致接受治疗的人群与普通人群有很大的不同。 而对因果性和因果关系的衡量,就是因果推断里最重要的课题。
1. Potential Outcome¶
潜在结果框架(Potential Outcome Framework)是研究因果关系的经典框架,它的作用是用来推断一个treatment对于结果的影响。
这里的treatment我认为可以理解为对研究对象施加的特定操作,研究对象也就是unit,它和前面所提到的医学实验中的个人(individual)实际上是同样的意思,但是因为很多因果问题不是在人的身上研究的,所以因果推断理论中,把atomic research object称为unit,即可以理解为最小的研究对象。 所有的treatment都是针对特定unit进行的,对于一个unit-treatment对,最终的结果就被称为potential outcome
下面这幅图用医学实验来简单说明了什么是potential outcome:
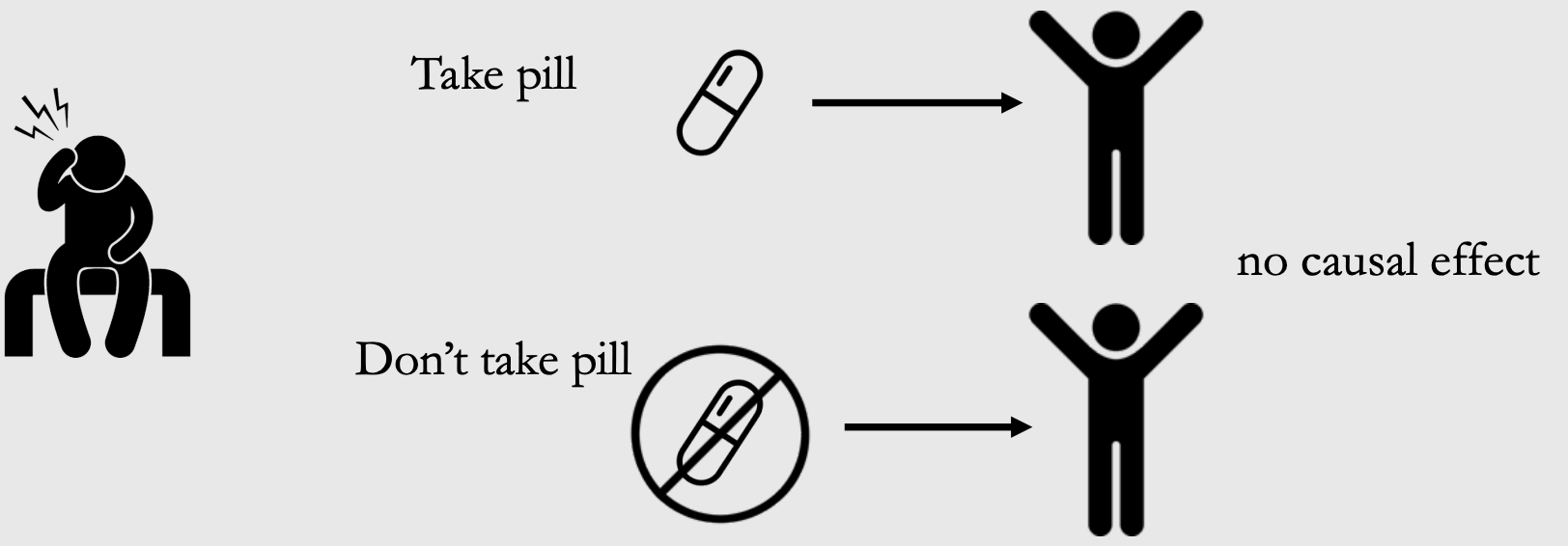
1.1 Basis¶
我们可以用\(T\)来表示treatment,然后用\(Y(t)\)来表示对应的结果,用i来表示一个unit,同样以上面的医学实验作为例子,第i个unit(即病人)在施加了吃药(\(T=1\))和不吃药(\(T=0\))两种treatment的情况下,对应的结果分别是\(Y_i(1), Y_i(0)\) (1代表健康,0代表继续生病),如下图所示:\
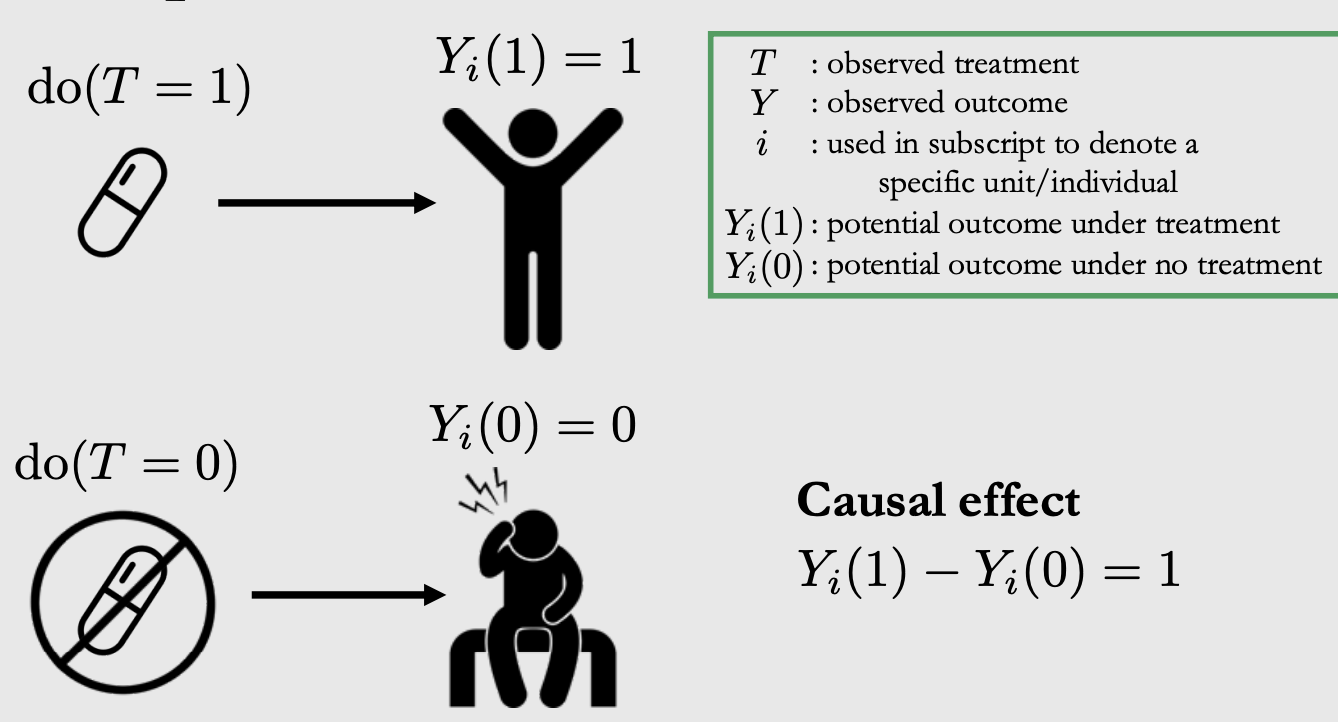
这样一来,在吃药的treatment下,一个病人的表现和不吃药的差别就是\(Y_i(1)- Y_i(0)=1\),这个结果就代表了吃药这个treatment对当前病人i的因果效应。我们称之为individual treatment effect (ITE),记为\(\tau\),它的计算方式是:
1.2 Fundamental Problem of Causality¶
虽然我们可以用上面的方法计算ITE,但是,对于一个给定的unit(individual)来说,要同时观察到所有的潜在结果是不可能的,就比如说,对于一个受试者,我可以观察到他吃了药之后的表现,也可以观察到他不吃药的表现,但是我们无法同时观察他吃药和不吃药对应的不同表现,这实际上就是因果推断中的基础问题。 我们观察到的结果被称为事实(factual),没有观察到的可能结果被称为反事实(counterfactuals),这是因为他们和事实是相反的。 - 值得注意的是,直到被观察到为止,我们不能确定谁是事实,而谁是反事实的。在此之前,他们都被叫做潜在结果。
1.3 Getting Around the Fundamental Problem¶
我们无法直接得到每个具体的unit的treatment effect,但是我们可以得到所有unit上的average treatment effect (ATE),ATE也叫做average causal effect (ACE),它的计算方式如下:
那么现在我们的问题就变成了如何计算\(\mathbb{E}[Y_i(1)]-\mathbb{E}[Y_i(0)]\),一个很容易产生的想法是,\(\mathbb{E}[Y_i(1)]-\mathbb{E}[Y_i(0)]=\mathbb{E}[Y|T=1]-\mathbb{E}[Y|T=0]\),这样一来,我们只需要对每个treatment,将它们对应的结果求一下期望再相减即可。以下面这张图的数据为例,计算得到的结果应该是⅓:
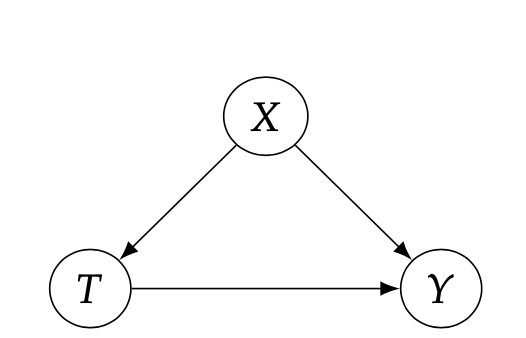
 但事实上,这种想法是错误的,因为这实际上弄混了因果性和关联性的区别,\(\mathbb{E}[Y_i(1)]-\mathbb{E}[Y_i(0)]\)是一个因果量,而\(\mathbb{E}[Y|T=1]-\mathbb{E}[Y|T=0]\)是一个关联量,他们二者是不等价的,这是因为表中的数据太少了,并且不是随机对照试验,而且这些真实数据中存在着混淆变量,会同时影响T和Y,如下图所示(下图的具体含义需要等后面章节因果图的时候在详细展开),但总的来说,上面的表达式是不成立的。
但事实上,这种想法是错误的,因为这实际上弄混了因果性和关联性的区别,\(\mathbb{E}[Y_i(1)]-\mathbb{E}[Y_i(0)]\)是一个因果量,而\(\mathbb{E}[Y|T=1]-\mathbb{E}[Y|T=0]\)是一个关联量,他们二者是不等价的,这是因为表中的数据太少了,并且不是随机对照试验,而且这些真实数据中存在着混淆变量,会同时影响T和Y,如下图所示(下图的具体含义需要等后面章节因果图的时候在详细展开),但总的来说,上面的表达式是不成立的。
那么我们应该怎么计算\(\mathbb{E}[Y_i(1)]-\mathbb{E}[Y_i(0)]\)呢?这实际上也是潜在结果框架要研究的主要问题,我们必须突破Causal Inference中这一基础问题,才能把因果表达式转化成统计表达式,这种能力被称为Identifiability(可识别性)
Identifiability的定义是:A causal quantity (e.g. \(\mathbb{E}[Y(t)]\)) is identifi- able if we can compute it from a purely statistical quantity (e.g. \(\mathbb{E}[Y|t]\)).
下一节内容我们将具体介绍潜在结果框架是如何基于一定的假设来计算因果量的。