CS224W:图机器学习9¶
本页统计信息
-
本页约 1867 个字, 预计阅读时间 6 分钟。
-
本页总阅读量次
传统的图生成模型¶
我们希望通过图生成模型来生成现实世界中的图,通过这种方式可以深入了解图的内在形式,并且可以预测一张图未来的变化趋势,进行图的异常检测。
真实世界中图的性质¶
我们通常使用一些关键的特征来描述一张图,比如度数的分布,聚类系数,连通分量,路径长度等。这些前面都已经讲过了,这里就不再一一介绍。同时前面还讲了随机图的生成方法,其中比较有用的是Erdős–Rényi 算法。
鲁棒性的衡量标准:Expansion¶
扩展性的定义是,对于图\(G=(V,E)\),对于任意的V的子集S,离开S的边的数量都大于\(\alpha \min(|S|,|V-S|)\),那么\(\alpha\)就被称为是图G的扩展性,即: $$ \alpha=\min \frac{\mathrm{# (edge \quad leaving \quad S)}}{\min(|S|,|V-S|)} $$
- 一个n个节点的图中至少存在\(O(\log n/\alpha )\)长度的路径
- 随机图因为有比较好的扩展性因此BFS所需的时间是\(\log N\)级别的
随机图模型中存在的问题¶
随机图模型通过随机的方式生成一张图,并且依然可以保持比较好的路径平均长度,聚类系数,度数分布等特征,但是也存在如下问题:
- 缺少局部特征,聚类系数太低
- 度数的分布缺乏真实性
- 难以生成实际图中可能存在的大分量
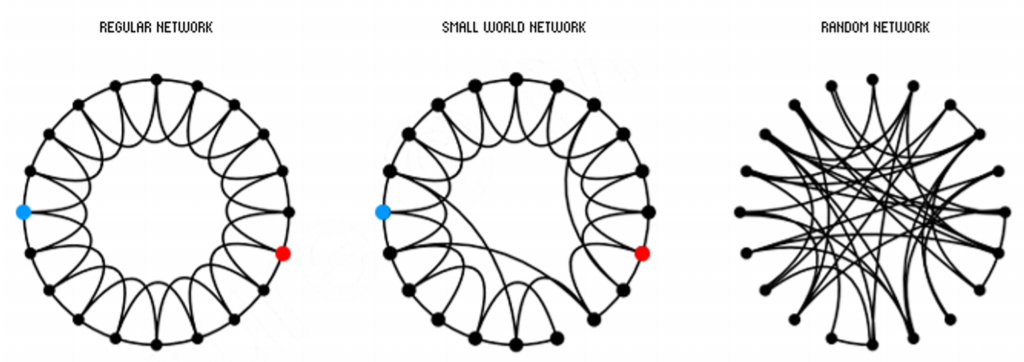
Small-World图模型¶
Small-World图模型提供了一种使用常规的点阵图和随机图进行插值(Interpolate)的办法来生成高聚类系数并且低路径长度(引申出一个概念叫做图的直径)
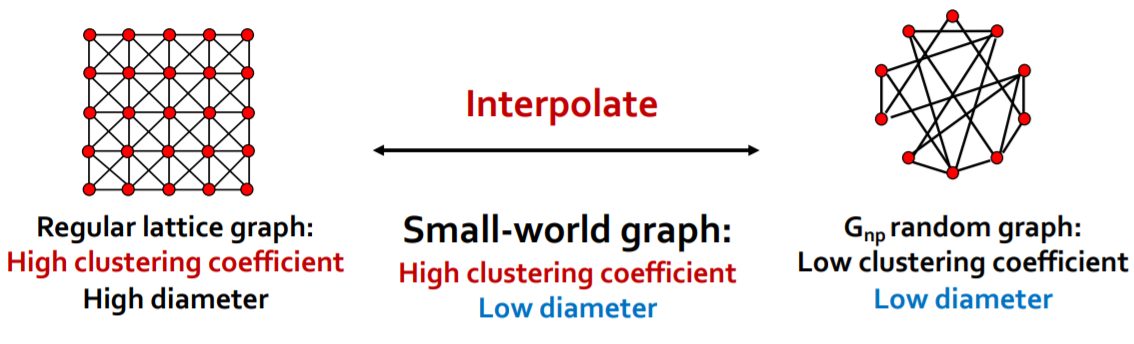
- 首先从一个普通的点阵图开始,然后在这个图中引入一定的随机性,随机添加/删除一些边
Knonecker模型¶
我们可以尝试使用递归的方法来生成图结构,而图结构的递归生成可以考虑自相似的方法,自相似指的就是整体和部分具有一定的相似性。而Knonecker模型就提供了一种生成自相似模型的方法
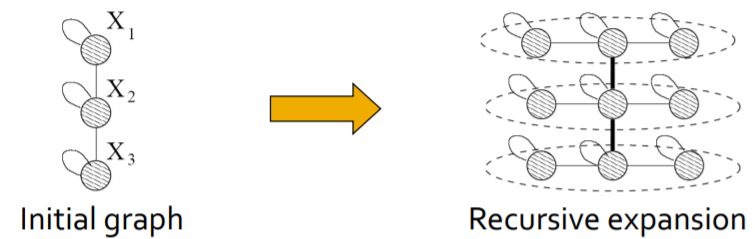
- 可以用两张图的邻接矩阵,定义其Knonecker作为生成图的邻接矩阵,Knonecker积的计算方式如下:
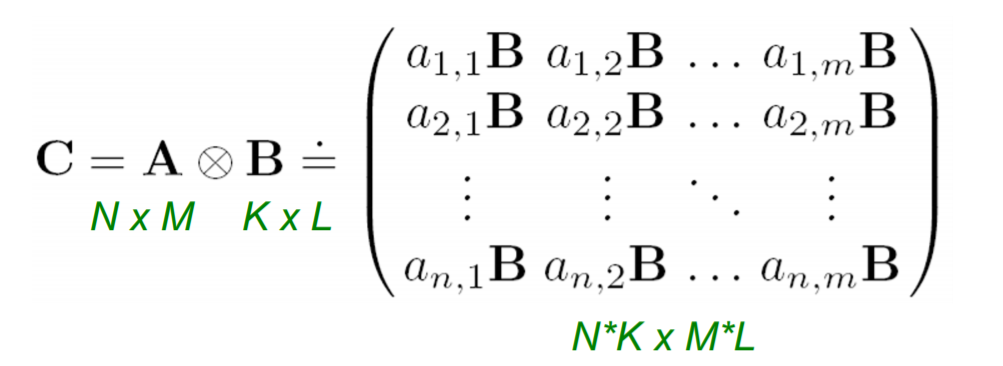
- 使用这种方法可以生成m阶的Knonecker图,即\(K_m=K_{m-1}\otimes K_1\),在此基础上
深度图生成模型¶
机器学习方法¶
基于机器学习方法的图生成模型主要需要从给定的\(p_{data}(G)\)中获得的数据分布,学习出数据的一个分布\(p_{model}(G)\),并且使用这个分布来生成所需要的图,我们用\(p_{data}(G,\theta)\)来表示模型,我们希望得到一个尽可能接近\(p_{data}(G)\)的结果,并且可以从这个模型中进行采样并生成结果。为此,我们可以使用极大似然法:
而图生成的过程中,我们可以先使用一个噪声分布\(z\sim N(0,1)\)来获取\(x_i= f(z_i;\theta)\)这里的f就可以使用一个神经网络,而\(x_i\)被理解为是一系列动作,比如增加节点和增加边,因此一张图的生成可以用链式法则来表示:
GraphRNN¶
模型简介¶
GraphRNN就是将图的构建看成了一种序列化的操作,即每次在图中添加节点或者在已有的节点中添加边(分别对应node-level和edge-level的任务),这样一来图的生成就变成了一个序列生成的问题,可以使用RNN来处理序列化的问题。
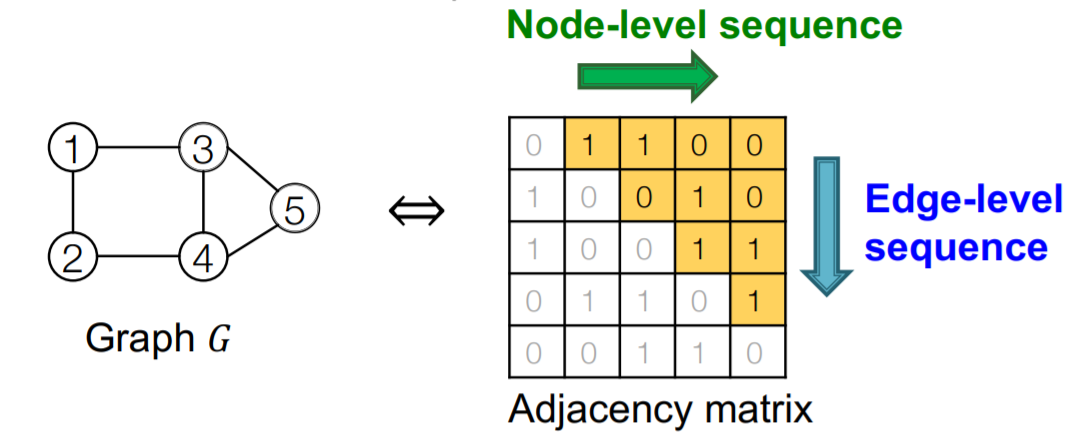
我们需要解决两个问题:
- 生成新节点的状态,表示在序列中增加一个节点
- 根据节点的状态来生成对应的边
因此GraphRNN包含了两个RNN,一个是节点级别的RNN,另一个是边级别的RNN,由Node-RNN来生成Edge-RNN的状态,并且由Edge-RNN来判断每一个新的节点是否会和前面的节点相连。
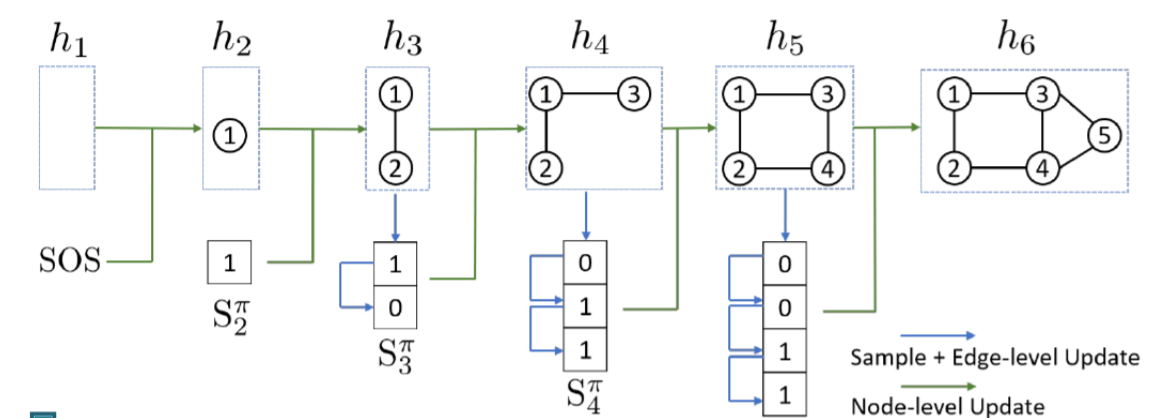
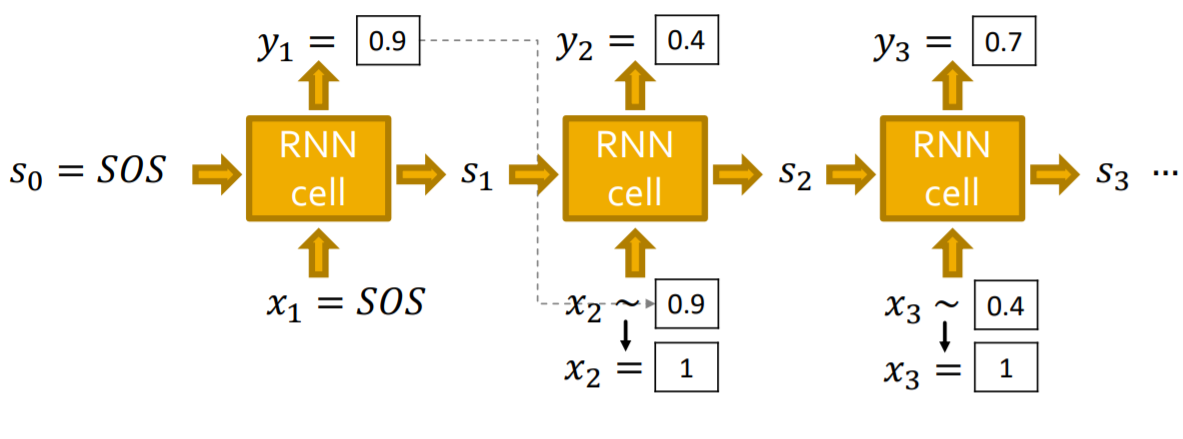
- 模型中使用SOS和EOS分别表示分别表示序列生成的开始和结束,同时我们可以将前一个的输出用作下一个的输入,来达到连续生成的目的
- 每一个步骤中RNN都会生成一个单条边的概率分布,然后从这个分布中进行采样,作为下一个步骤的输入
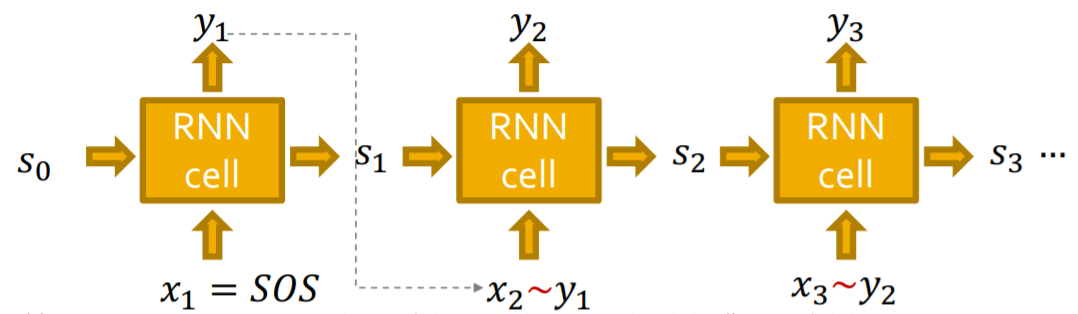
模型的训练和测试¶
在测试阶段,模型的运行方式如下,使用上一步的输出结果y生成下一个x的伯努利分布,然后进行采样得到x进行下一步。
而在训练的过程中还需要进行Teacher Forcing,计算其损失函数并进行参数优化,这里损失函数一般使用交叉熵,即
$$ L=-\left[y_{1}^{} \log \left(y_{1}\right)+\left(1-y_{1}^{}\right) \log \left(1-y_{1}\right)\right] $$ 使用损失函数反向传播进行梯度优化可以使得预测结果\(y_i\)适应于输入数据的真实分布\(y_i^{*}\),同时运行的过程中,一个图的生成可以分成以下几个步骤:
- 增加新结点:运行一个步骤的Node-RNN并且将其输出输入Edge-RNN进行初始化
- 给新节点添加新边:运行一次Edge-RNN并预测新的节点是不是会和前面的若干个节点相连
- 添加新节点:用最新的Edge-RNN的隐层作为输入运行一个步骤的Node-RNN
- 停止生成:当Edge-RNN输出EOS的时候就停止生成
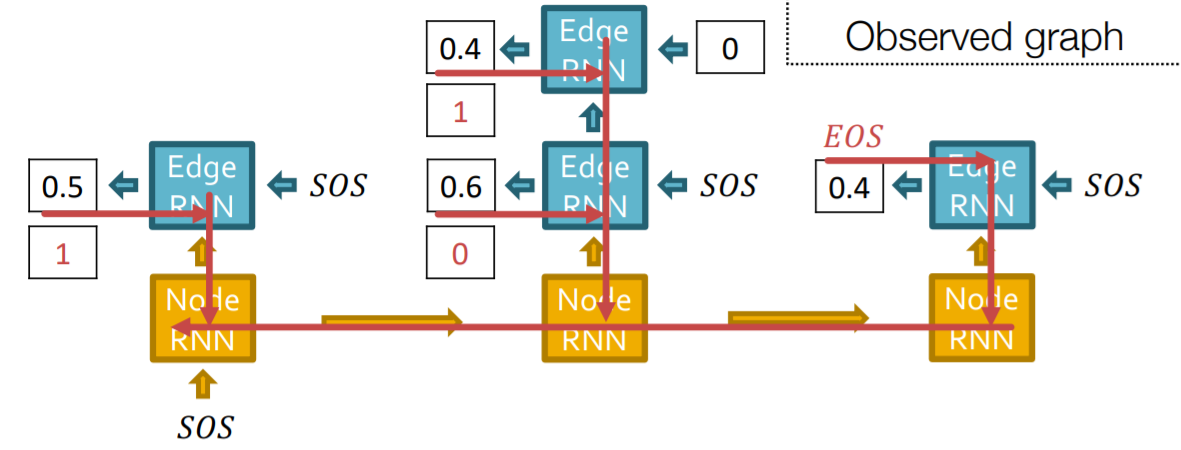
- 测试的时候和训练阶段最大的不同是,训练的时候要保留Edge-RNN获得的概率并将其用在loss的计算上,但是测试的时候直接按照概率分布来预测这条边存不存在并生成最后的结果。
存在的问题¶
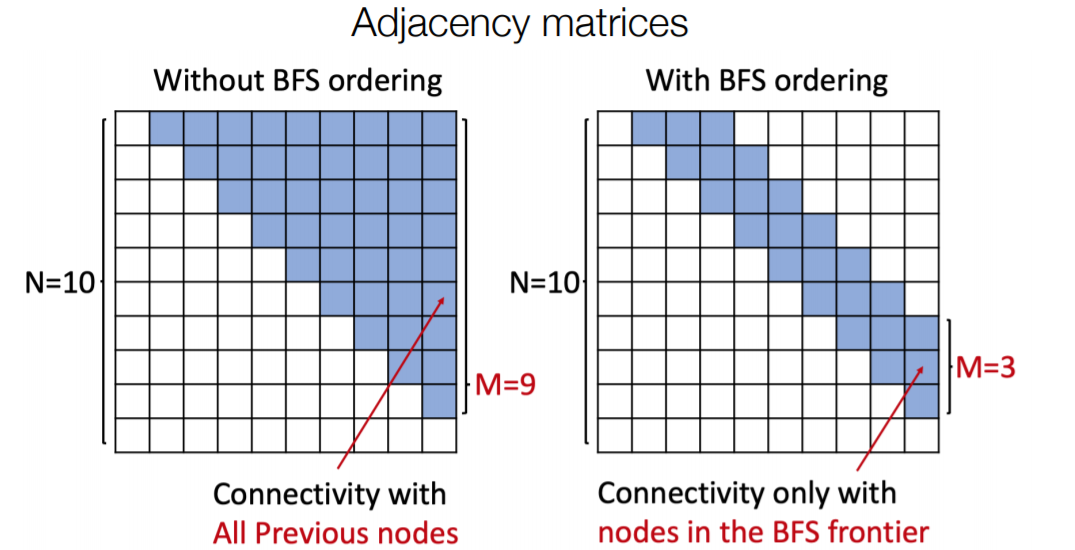
图RNN生成一张图的过程比较复杂,对于要生成长路径的任务场景下表现不太好(这就好像NLP中的RNN会对长距离的依赖关系学习效果不佳一样),使用BFS的方法可以降低生成过程的复杂度。
评估生成的图¶
另一个很重要的问题是生成的图要怎么评估图生成模型生成的图的质量,我们可以用相似度的方式来定义生成图和真实图的相似性。而相似度的定义主要有两种方式,一种是Visual Similarity,也就是使用眼睛来看,另一种方式是基于图统计信息的相似度,比如度数分布、聚类系数分布和轨道数等等。
Earth Mover Distance (EMD)可以用来评估两个分布之间的相似性,计算方式是计算将一个分布“移动成”另一个分布所需要付出的代价,而Maximum Mean Discrepancy (MMD)通过将图划分成两个集合进行相似度的比较,可以用来评估n个图之间的相似性。