Stanford-CS231N-Assignment札记8:自监督学习与课程总结¶
本页统计信息
-
本页约 1527 个字, 99 行代码, 预计阅读时间 6 分钟。
-
本页总阅读量次
Stanford2021年春季课程CS231N:Convolutional Neural Networks for Visual Recognition的一些作业笔记,这门课的作业围绕视觉相关的任务,需要从底层手动实现一大批经典机器学习算法和神经网络模型,本文是作业的第八部分,包含了自监督学习和整个课程的总结
自监督学习Self-Supervised Learning¶
自监督学习的概念¶
自监督学习(Self-supervised Learning)是这几年机器学习和深度学习领域非常火热的一个研究方向,这种学习方式可以在数据没有标注的情况下学到好的数据表示,并且这种方式取得了巨大的成功,因为实际场景中,很多数据集都是没有标注或者难以标注的(要花费大量的成本),而自监督学习可以在数据没有标注的情况下就学到足够好的数据表示,并可以将其用到下游任务中。
另一个问题是,什么样的表示才是一个好的表示,一般我们认为能够尽可能提取数据中的重要特征并将其编码到向量空间中的才是好的表示,同时具有相似特征的数据,它们的表示向量也应该相似,比如两张图片中如果表示的是同一个物体,那么他们的表示向量应该比较接近,否则两张图的表示向量应该会有很大的差别,
对比学习Contrastive Learning¶
对比学习就是一种常见的自监督学习方式,这个作业中需要实现的其实就是一个经典的对比学习算法SimCLR,对比学习的一个基本想法是,给相似的数据学习出相似的表示,而不相似的数据学习出不相似的表示,也就是说数据的特征是通过对比得到的。
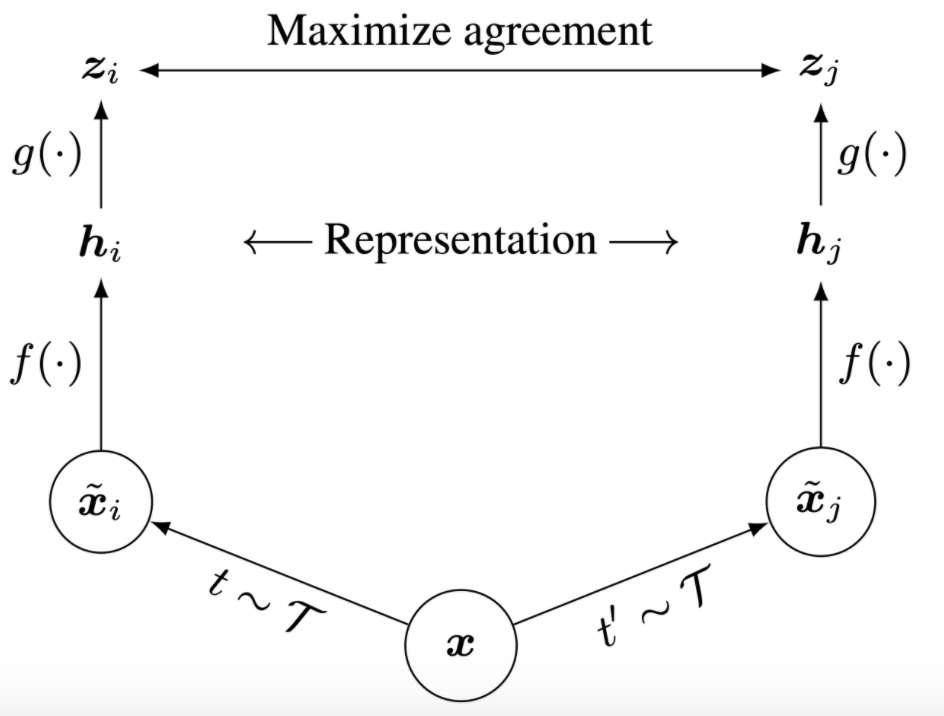
那么我们怎么得到两张相似的图片和两张不相似的图片呢?自监督学习使用的数据是没有标注的,因此我们不能用label来确定数据之间是否相似,而对于图像来说,答案就是可以用图像的各种变换自己生成两张相似的图像,称为一个positive pair,然后以这两张图像是高度相似的为先验知识来进行训练,训练过程中,我们希望得到这两张图尽可能相似的表示,这个过程可以用下面的这张图来表示:
模型的实现¶
作业中使用了已经预训练过的CNN模型来帮助完成任务,有论文研究表明,使用预训练过的模型进行对比学习的效果要好于从头开始训练。
数据增强¶
首先我们要实现的就是一个数据增强的模块,我们通过输入一张图片,并将其进行一定的随机变换得到两张相似但是不完全相同的图片,这里可以使用torchvision.transform中的API来对图片进行各种各样的处理操作,具体的有:
def compute_train_transform(seed=123456):
random.seed(seed)
torch.random.manual_seed(seed)
# Transformation that applies color jitter with brightness=0.4, contrast=0.4, saturation=0.4, and hue=0.1
color_jitter = transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)
train_transform = transforms.Compose([
# Step 1: Randomly resize and crop to 32x32.
transforms.RandomResizedCrop(32),
# Step 2: Horizontally flip the image with probability 0.5
transforms.RandomHorizontalFlip(p=0.5),
# Step 3: With a probability of 0.8, apply color jitter
# (you can use "color_jitter" defined above.
transforms.RandomApply([color_jitter], p=0.8),
# Step 4: With a probability of 0.2, convert the image to grayscale
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
return train_transform
- 根据作业的要求,我们要按照顺序并以一定的概率对一张图片分别进行调整大小,随机的水平翻转,随机的颜色变换,随机的灰度化等操作。
定义损失函数¶
另一个重要的问题就是我们如何定义训练时候的损失函数,在对比学习中我们的一条数据实际上是两个相似的图像,因此我们要计算他们之间的相似度,并且让相似度最小化,这样才能达成我们的训练目标。因此我们需要定义两个图像表示之间的相似度,进而继续定义出训练时候的损失函数,而SimCLR中,对相似度和损失函数的定义是: $$ \mathrm{sim}(z_i, z_j) = \frac{z_i \cdot z_j}{|| z_i || || z_j ||} $$
这里采用的相似度函数其实就是余弦相似度,而损失函数则进一步和一个批次N组数据中的其他2N张图片都进行了对比,起到突出当前一组图片是最相似的这个目的。因此一个小批量数据的总体loss函数就被定义成了 $$ L = \frac{1}{2N} \sum_{k=1}^N [ \; l(k, \;k+N) + l(k+N, \;k)\;] $$ 下面我们就来实现整个loss的计算过程:
def sim(z_i, z_j):
norm_dot_product = torch.dot(z_i, z_j) / (torch.linalg.norm(z_i) * torch.linalg.norm(z_j))
return norm_dot_product
def simclr_loss_naive(out_left, out_right, tau):
N = out_left.shape[0] # total number of training examples
# Concatenate out_left and out_right into a 2*N x D tensor.
out = torch.cat([out_left, out_right], dim=0) # [2*N, D]
total_loss = 0
for k in range(N): # loop through each positive pair (k, k+N)
z_k, z_k_N = out[k], out[k + N]
exp_sum1, exp_sum2 = 0, 0
for i in range(2 * N):
if i != k:
exp_sum1 += torch.exp(sim(z_k, out[i]) / tau)
if i != k + N:
exp_sum2 += torch.exp(sim(z_k_N, out[i]) / tau)
total_loss += -torch.log(torch.exp(sim(z_k, z_k_N) / tau) / exp_sum1)
total_loss += -torch.log(torch.exp(sim(z_k_N, z_k) / tau) / exp_sum2)
# In the end, we need to divide the total loss by 2N, the number of samples in the batch.
total_loss = total_loss / (2 * N)
return total_loss
def sim_positive_pairs(out_left, out_right):
pos_pairs = None
left_norm = out_left / torch.linalg.norm(out_left, dim=-1, keepdim=True)
right_norm = out_right / torch.linalg.norm(out_right, dim=-1, keepdim=True)
mul = torch.mm(left_norm, right_norm.T)
pos_pairs = torch.diag(mul).view(-1, 1)
return pos_pairs
def compute_sim_matrix(out):
out_norm = out / torch.linalg.norm(out, dim=1, keepdim=True)
sim_matrix = torch.mm(out_norm, out_norm.T)
return sim_matrix
def simclr_loss_vectorized(out_left, out_right, tau, device='cuda'):
N = out_left.shape[0]
# Concatenate out_left and out_right into a 2*N x D tensor.
out = torch.cat([out_left, out_right], dim=0) # [2*N, D]
# Compute similarity matrix between all pairs of augmented examples in the batch.
sim_matrix = compute_sim_matrix(out) # [2*N, 2*N]
# Step 1: Use sim_matrix to compute the denominator value for all augmented samples.
# Hint: Compute e^{sim / tau} and store into exponential, which should have shape 2N x 2N.
exponential = torch.exp(sim_matrix / tau)
# This binary mask zeros out terms where k=i.
mask = (torch.ones_like(exponential, device=device) - torch.eye(2 * N, device=device)).to(device).bool()
# We apply the binary mask.
exponential = exponential.masked_select(mask).view(2 * N, -1) # [2*N, 2*N-1]
# Hint: Compute the denominator values for all augmented samples. This should be a 2N x 1 vector.
denom = torch.sum(exponential, dim=1, keepdim=True)
# Step 2: Compute similarity between positive pairs.
# You can do this in two ways:
# Option 1: Extract the corresponding indices from sim_matrix.
# Option 2: Use sim_positive_pairs().
sim_pairs = sim_positive_pairs(out_left, out_right)
sim_pairs = torch.cat([sim_pairs, sim_pairs], dim=0)
# Step 3: Compute the numerator value for all augmented samples.
numerator = torch.exp(sim_pairs / tau)
# Step 4: Now that you have the numerator and denominator for all augmented samples, compute the total loss.
loss = torch.mean(-torch.log(numerator / denom))
return loss
后面的内容因为需要GPU,当时做的时候到这一步就没有再做下去,反正测试点都已经通过,就暂时先到这里结束了吧。
课程总结¶
到这里这门课程的学习基本也就结束了,CS231N无疑是入门深度学习和神经网络的最佳课程没有之一,不过我学这门课的时候并没有听他的lecture而是直接从作业入手,虽然自以为有了一点点的深度学习和机器学习的基础,但是真的做起这些有难度的作业来还是感受到了很大的困难,不过最后还是做完了,这些作业不仅从头开始实现了常见神经网络模型,这些作业串联起来也是一部简单的深度学习发展史,从传统的统计机器学习开始,到MLP,CNN,RNN,Transformer,从最传统的有监督学习,到使用各种trick防止过拟合增强模型的鲁棒性,再到生成模型,对抗训练和自监督学习,作业一步步为我们呈现了深度学习的发展历程,我们在完成作业的同时,也可以感受到深度学习作为一个data-driven的研究领域的研究思潮的变迁。